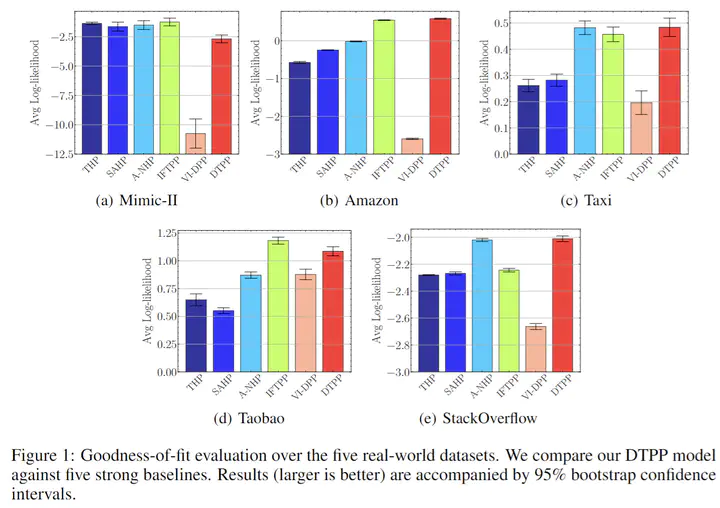
Abstract
The standard paradigm of modeling marked point processes is by parameterizing the intensity function using an attention-based (Transformer-style) architecture. Despite the flexibility of these methods, their inference is based on the computationally intensive thinning algorithm. In this work, we propose a framework where the advantages of the attention-based architecture are maintained and the limitation of the thinning algorithm is circumvented. The framework depends on modeling the conditional distribution of inter-event times with a mixture of log-normals satisfying a Markov property and the conditional probability mass function for the marks with a Transformer-based architecture. The proposed method attains state-of-the-art performance in predicting the next event of a sequence given its history. The experiments also reveal the efficacy of the methods that do not rely on the thinning algorithm during inference over the ones they do. Finally, we test our method on the challenging long-horizon prediction task and find that it outperforms a baseline developed specifically for tackling this task; importantly, inference requires just a fraction of time compared to the thinning-based baseline.